Mit Flow Design flüssig entwickeln
Ein Softwareentwicklungsprozess, der ein Team sicher von den Anforderungen zum Code führt, muss die folgenden Schritte berücksichtigen:
Anforderungen
- Anforderungen vertikal zerlegen
- Entwurf in die Breite
- Eine Anforderung auswählen
- Entwurf in die Tiefe
- Arbeitsorganisation
- Arbeitsteilige Implementation (inkl. Tests)
- Integration (inkl. Tests)
- Code Review
Code
Die Organisation eines Teams sollte so erfolgen, dass das Team zu einem gegebenen Zeitpunkt gemeinsam an einer Sache arbeitet. Im Rahmen von Kanban spricht man vom Work in Progress (WIP). Durch ein WIP Limit von eins sorgt das Team dafür, dass die eine Sache mit maximaler Geschwindigkeit voran kommt. Gleichzeitig reduziert das Team damit die Wahrscheinlichkeit, dass ein systematischer Fehler an mehreren Stellen Probleme verursacht. Ferner wird durch die nicht notwendigen Kontextwechsel effizient und fokussiert an einem Thema gearbeitet.
Natürlich wird das Ideal von eins nur selten erreicht. Dennoch müssen die gleichzeitig in Bearbeitung befindlichen Teile minimiert werden. Dazu ist es allerdings erforderlich, dass ein Team gemeinsam an einem Feature arbeiten kann. Mangels Entwurf fehlt vielen Teams die Phantasie, wie dies effizient praktiziert werden könnte.
Die erste Voraussetzung, um sinnvoll in einen Entwurf der Lösung einsteigen zu können, liegt darin, den Umfang klein zu halten. Die Anforderungen müssen dazu systematisch zerlegt werden. Mit Recht wird Big Design Upfront kritisiert, wobei die Betonung hier auf „Big“ liegt. Gegen einen Entwurf vor der Umsetzung ist nichts einzuwenden, ganz im Gegenteil.
Wenn ein Team die Anforderungen zerlegen möchte, benötigt es eine Hierarchie von Elementen, in die die Anforderungen zerfallen. Es genügt nicht, von einem Epic mit darin enthaltenen User Stories auszugehen.
Im Rahmen von Flow Design haben wir eine Hierarchie zur Zerlegung der Anforderungen definiert, die in Abbildung 1 zu sehen ist. Die oberste Ebene ist das Softwaresystem. Das System an oberster Stelle der Hierarchie umfasst sämtliche Anforderungen. Ausreichend große Systeme zerfallen dann in mehrere Bounded Contexts. Der Begriff wurde von Eric Evans im Domain Driven Design geprägt. Ein Bounded Context ist dadurch charakterisiert, dass er über die Hoheit seiner Datenhaltung verfügt. In jedem Bounded Context kann entschieden werden, welche Form der Datenhaltung verwendet wird.
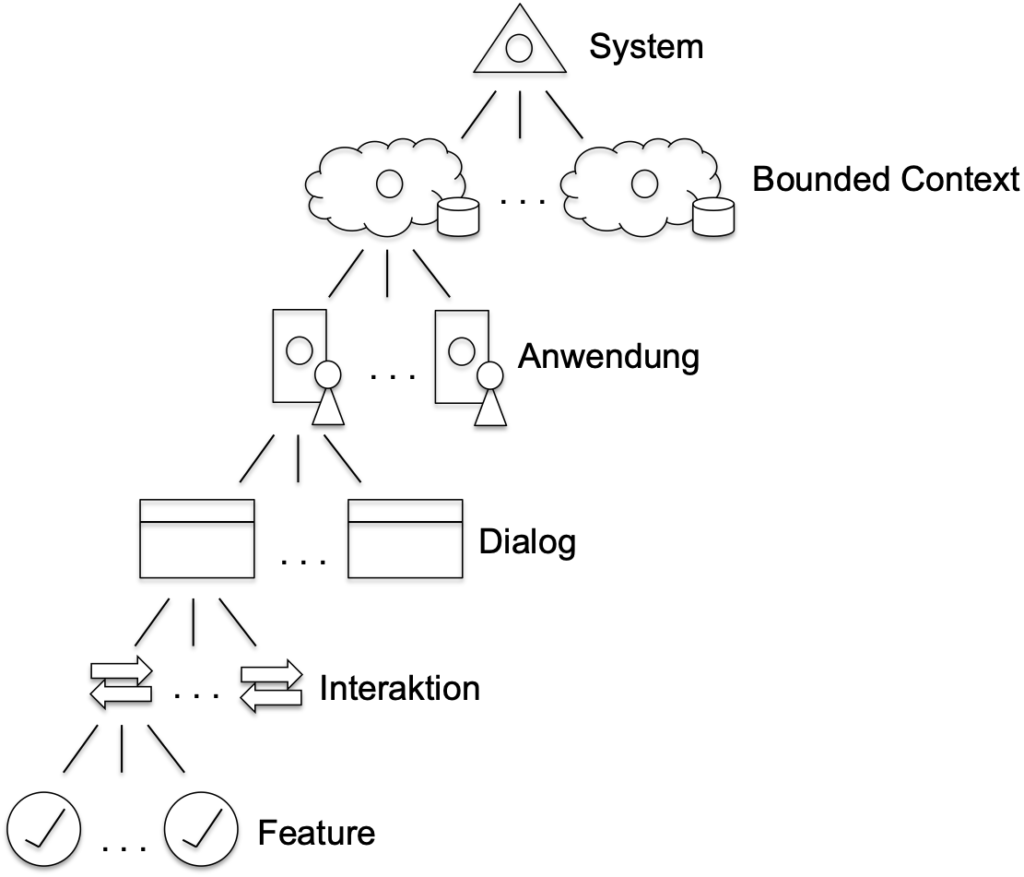
Innerhalb eines Bounded Context zerfallen die Anforderungen in unterschiedliche Anwendungen. Diese sind dadurch charakterisiert, dass sie den jeweiligen Rollen eine jeweils angemessene Benutzerschnittstelle zugestehen. Ein Admin möchte eine scriptingfähige Konsolenanwendung, ein „normaler“ Benutzer eine grafische Benutzerschnittstelle, etc. Auf dieser Ebene gliedern sich die unterschiedlichen Anforderungen eines Bounded Context in jeweils einzelne Anwendungen weiter auf.
Innerhalb einer Anwendung finden sich die Anforderungen dann in unterschiedlichen Dialogen wieder. Dem liegt die Idee zu Grunde, dass ein Anwender immer mit der Anwendung interagieren muss. Würde er dies nicht tun, gäbe es keinen Grund, Domänenlogik zu implementieren. Erst dadurch, dass der Anwender auf eine Schaltfläche klickt, einen Menüpunkt auswählt, eine Anwendung startet, etc. ergibt sich die Notwendigkeit, das gewünschte Verhalten zu realisieren. Die Interaktionen eines Anwenders finden innerhalb eines Dialog statt. Konkret bedeutet ein Dialog ein Formular, Fenster, Window, etc. Innerhalb eines solchen Dialogs sind meist unterschiedliche Interaktionen möglich. Es können Schaltflächen angeklickt werden, Menüpunkte ausgewählt werden, etc. Manche Interaktionen bleiben im selben Dialog, andere Interaktionen führen den Anwender vom einen in einen anderen Dialog. Durch die Interaktionen eines Dialogs werden die Anforderungen somit erneut kleiner geschnitten.
Bis hierher haben wir die gesamten Anforderungen jeweils auf einzelne Elemente aufgeteilt. Die gesamten Anforderungen eines Systems sind beispielsweise aufgeteilt auf mehrere Bounded Contexts. Oder die gesamten Anforderungen eines Dialogs sind aufgeteilt auf mehrere Interaktionen innerhalb dieses Dialogs. Unterhalb der Interaktion finden wir dann Features. Bei diesen geht es nun nicht mehr um eine vollständige Zerlegung, sondern um die Frage, was zunächst bei Entwurf und Implementation weggelassen werden kann. Wir erinnern uns, nach ein bis zwei Tagen soll bereits ein Durchstich geliefert werden. Die Domänenlogik, die mit einer einzelnen Interaktion verbunden ist, kann bereits zu groß sein, um sie in zwei Tagen zu realisieren. Daher geht es in diesem Fall darum, Features zu identifizieren, die zeitlich verschoben werden, um schnell zu einem Durchstich und damit zu Feedback zu gelangen. Es ist auf dieser Ebene also nicht erforderlich, eine Interaktion vollständig in ihre Features zu zerlegen.
Typische Beispiele für Features, die zunächst weggelassen werden können, sind die Validierung der Benutzereingabe oder Spezialfälle. Verschiebt man das Feature Validierung zunächst, ist der Durchstich schneller realisiert. Der Product Owner kann sein Feedback geben zum Verhalten der Anwendung, solange der Anwender das Programm richtig bedient. Erst wenn das gewünschte Verhalten abgesegnet ist, kommen weitere Features an die Reihe. Nicht zur Disposition steht hier übrigens die Strategie, Tests zunächst wegzulassen! Es wird zu jedem Zeitpunkt auf die Clean Code Developer Werte Korrektheit und Wandelbarkeit gesetzt.
Mit Hilfe der hier aufgezeigten Hierarchie sind Teams in der Lage, die Anforderungen klar strukturiert zu zerlegen. Ferner gibt es bei dieser Vorgehensweise einen klar definierten Übergang von den Anforderungen in den Entwurf.
Beispiel
Bevor wir zum Entwurf übergehen, soll die Zerlegung von Anforderungen an einem Beispiel gezeigt werden. Als Beispiel dient eine Konsolenanwendung, mit der ein Anwender seitenweise durch CSV Dateien blättern kann. Abbildung 2 zeigt das Programm in Aktion.
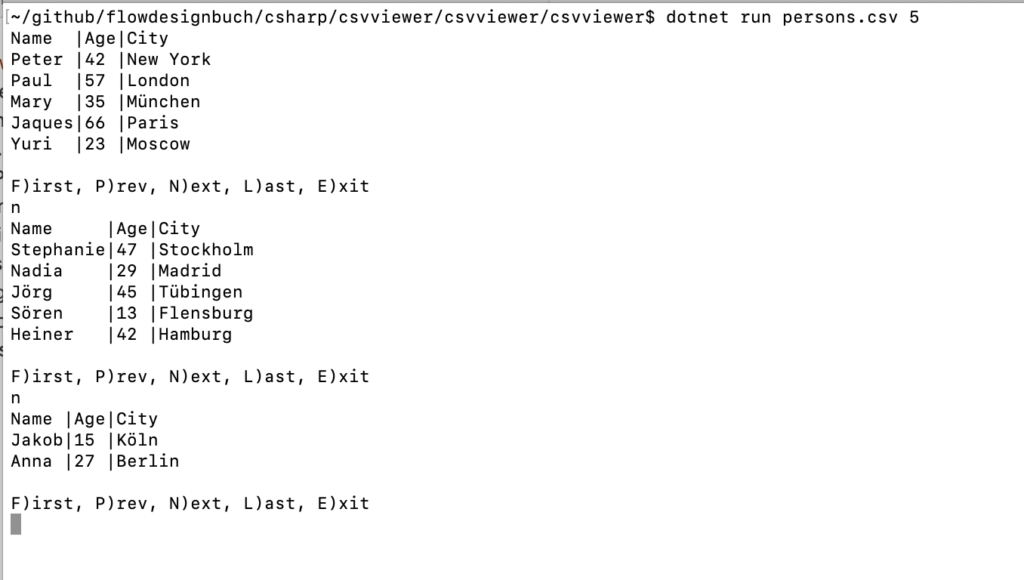
Das Softwaresystem „CSV Viewer“ besteht lediglich aus einem Bounded Context und dieser enthält nur eine Anwendung. In der Anwendung existiert nur ein einziger Dialog, in dem alle Interaktionen stattfinden. Auf der nächsten Ebene wird es interessant: welche Möglichkeiten der Interaktion hat der Anwender in diesem Dialog? Abbildung 3 zeigt das Ergebnis.
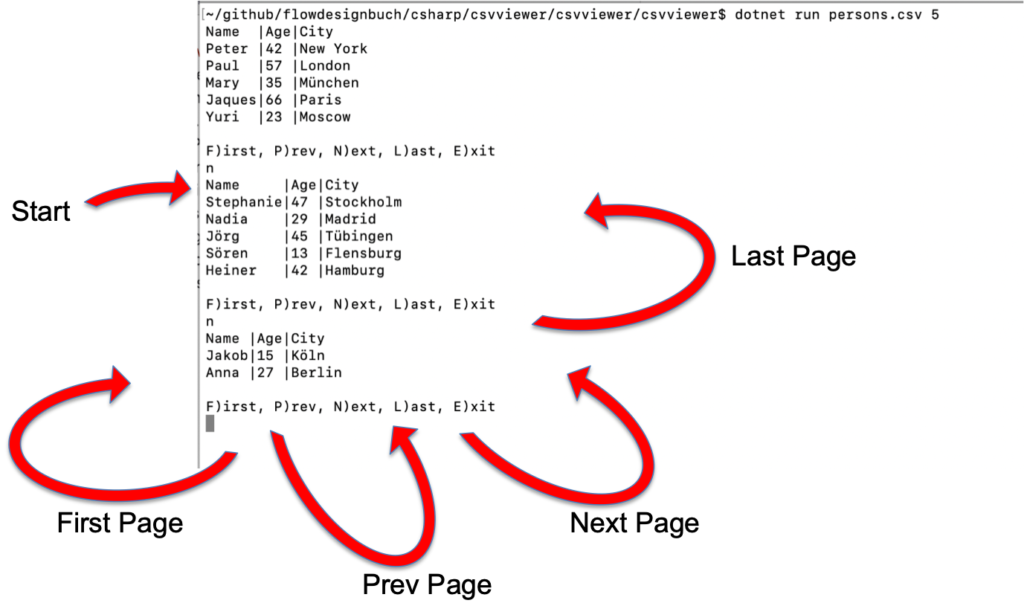
Die erste Interaktion des Anwenders ist das Starten der Anwendung. Streng genommen interagiert er hier noch nicht mit dem Dialog sondern mit dem Betriebssystem. Aus diesem Grund zeigt der Interaktionspfeil von außen, in dem Fall vom Betriebssystem, auf den Dialog. Der Start der Anwendung ist im Sinne der Anforderungszerlegung relevant, weil dabei bereits Domänenlogik erforderlich ist. Beim Verlassen der Anwendung, im Menü über den Punkt „E)xit“ erreichbar, ist das anders. Hierbei wird keine Domänenlogik erforderlich, weil beim Verlassen der Anwendung nichts spezielles passieren muss, was den CSV Viewer auszeichnet. Es ist zwar Logik erforderlich, aber keine Domänenlogik.
Domänenlogik ist solche Logik, die das Thema der Anwendung betrifft.
Bleiben die vier Interaktionen zum seitenweisen Blättern in den Daten. Diese Interaktionspfeile starten jeweils im Dialog und enden im selben Dialog. Damit wird ausgedrückt, dass die Kontrolle nach Ausführung der zugehörigen Domänenlogik wieder in den selben Dialog zurückführt.
Selbst in diesem kleinen Beispiel gelingt es, mit Hilfe der oben gezeigten Hierarchie von Anforderungselementen eine Zerlegung vorzunehmen. Jede einzelne Interaktion stellt ein potentielles Inkrement dar. Der Product Owner kann jeweils entscheiden, mit welchem Inkrement die Entwicklung begonnen bzw. fortgesetzt werden soll. Es muss nicht alles auf einmal betrachtet werden. So ist bei diesem Beispiel sogar eine Aufteilung der gesamten Anforderungen dergestalt möglich, dass die Inkremente im Bereich von Stunden realisierbar sind. Aus meiner langjährigen Erfahrung mit vielen Teams kann ich berichten, dass eine Aufteilung der Anforderungen in Inkremente, die innerhalb von ein bis zwei Tagen realisiert werden können, bislang immer funktioniert hat.
Übergang zum Entwurf
Aus der Zerlegung der Anforderungen kann nun der Übergang in den Entwurf erfolgen. Dazu werden zunächst alle Interaktionen eines Dialogs zusammenhängend betrachtet. Der sich daraus ergebende Entwurf in die Breite dient dazu, Aspekte zu betrachten, die mehrere Interaktionen betreffen. Das sind zum einen die Daten, die vom Dialog zur Domänenlogik und ggf. wieder zurück zu einem Dialog fließen. Ferner betrifft es die Frage, wo in der Anwendung Zustand gehalten wird.
Die bei Flow Design verwendeten Entwurfsdiagramme sind Datenflussdiagramme.
Für das Beispiel CSV Viewer zeigt die Abbildung 4 den Entwurf in die Breite. Für jede Interaktion ist ein Datenfluss gezeigt.
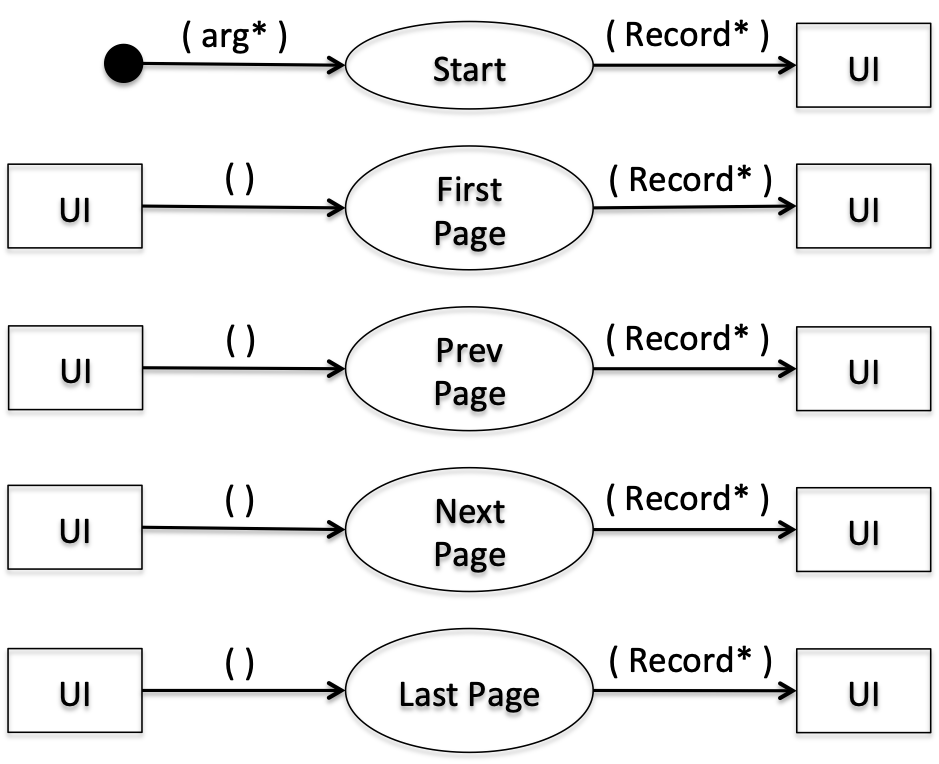
Nachdem sich das Team durch den Entwurf in die Breite einen Überblick verschafft hat, wählt es gemeinsam mit dem Product Owner eine einzelne Anforderung aus, die im Folgenden detailliert entworfen und dann umgesetzt wird.
Entwurf in die Tiefe
Der jetzt anstehende Entwurf in die Tiefe hat zum Ziel, das Problem so tief zu durchdringen, dass es im Anschluss arbeitsteilig implementiert werden kann. Das Ergebnis des Entwurfs sind die Kontrakte für Klassen und Methoden. Die Detaillierung erfolgt so tief, dass eine Trennung aller Aspekte sichergestellt ist. Jede Methode ist für nur genau einen Aspekt zuständig. Dadurch, dass die Methoden und nicht die Klassen im Entwurf im Vordergrund stehen, fällt es leicht, sie anschließend sinnvoll zu Klassen zusammenzufassen bzw. nicht zusammengehörendes klar zu trennen. Abbildung 5 zeigt den Entwurf für die Interaktion Start. Jede Ellipse ist eine Funktionseinheit, die als Methode implementiert wird. In grün unterhalb der Methoden stehen die Klassennamen.
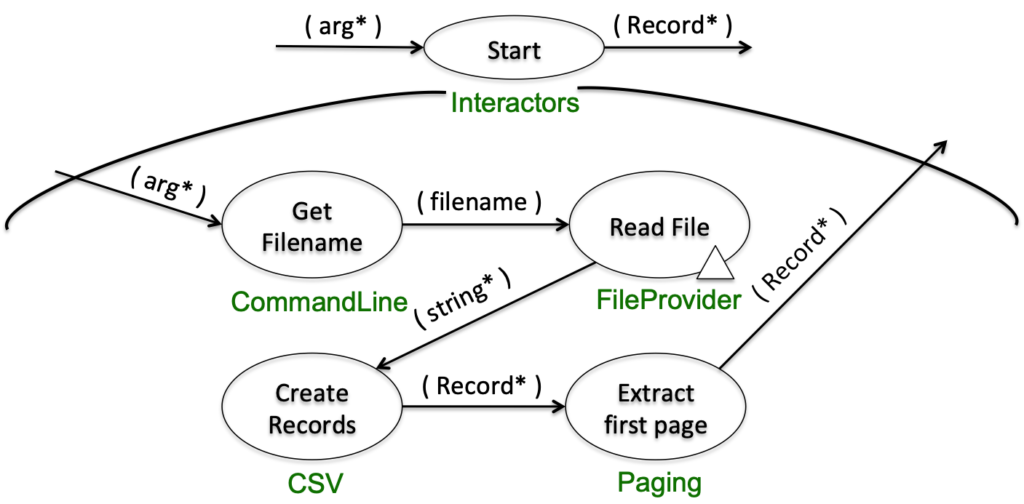
Durch den hohen Detaillierungsgrad kann die gemeinsame arbeitsteilige Implementation leicht organisiert werden. Vereinfacht gesagt werden hierbei den einzelnen Entwicklern Klassen zugeordnet, für deren Implementation sie jeweils zuständig sind. Die Implementation erfolgt selbstverständlich inklusive automatisierter Tests, typischerweise test-first.
Sobald die Implementation der Bestandteile abgeschlossen ist, können diese integriert werden. Grundsätzlich ist es durch den Einsatz von Interfaces möglich, den Integrationscode bereits zu erstellen, obschon die konkreten Implementationen noch nicht zur Verfügung stehen. Hierbei ist im Einzelfall abzuwägen, ob die Integration parallel zur Implementation der zu integrierenden Klassen erfolgt, oder ob dies im Anschluss angegangen wird. Zu diesem Zeitpunkt werden dann auch die automatisierten Integrationstests ergänzt, die sicherstellen, dass die isoliert getesteten Bestandteile auch im Zusammenspiel korrekt arbeiten.
Code Review
Den Abschluss der Iteration bildet ein gemeinsames Code Review. Dabei schaut das Team sich gemeinsam den gesamten Code an, der in den zurückliegenden ein bis zwei Tagen entstanden ist. Mit etwas Übung wird dafür in der Regel ein Zeitrahmen von lediglich 45-60 Minuten benötigt. Der Aufwand lohnt sich, da Code Reviews gleich mehrere Zwecke erfüllen. Neben der Kontrolle der Codequalität wird auf die korrekte Umsetzung der Anforderungen geschaut. Fehlende Testfälle werden genauso besprochen wie durchzuführende Refactorings. Neben diesen offensichtlichen Zielen eines Reviews dienen diese auch dazu, die Zusammenarbeit des Teams zu schärfen. Es wird Know How bezogen auf die Domäne sowie bezogen auf die verwendeten Sprachen und Plattformen im Team geteilt.
Fazit
Ob Scrum oder Kanban, Teams müssen diesen Rahmen mit einem Softwareentwicklungsprozess füllen. Mit Flow Design steht eine erprobte Methodik zur Verfügung. Sie zeichnet sich dadurch aus, dass sie eine strukturierte Vorgehensweise anbietet für die Zerlegung der Anforderungen sowie den Entwurf mit Datenflussdiagrammen. Durch den Entwurf ist eine arbeitsteilige Umsetzung leicht möglich, so dass es zu wirklicher Zusammenarbeit im Team kommt.
Eine Beispielimplementation ist zu finden unter https://github.com/slieser/flowdesignbuch/tree/master/csharp/csvviewer/csvviewer